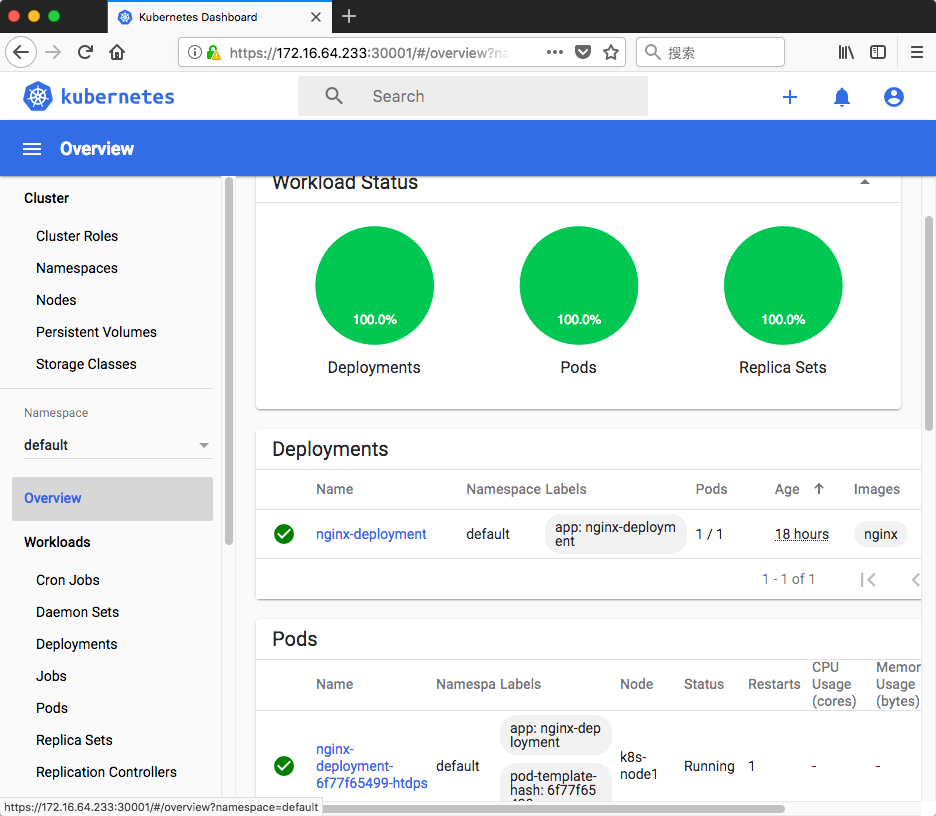
kubectl apply -f kubernetes-dashboard.yaml namespace/kubernetes-dashboard unchanged serviceaccount/kubernetes-dashboard unchanged service/kubernetes-dashboard created secret/kubernetes-dashboard-certs created secret/kubernetes-dashboard-csrf created secret/kubernetes-dashboard-key-holder created configmap/kubernetes-dashboard-settings created role.rbac.authorization.k8s.io/kubernetes-dashboard created clusterrole.rbac.authorization.k8s.io/kubernetes-dashboard created rolebinding.rbac.authorization.k8s.io/kubernetes-dashboard created clusterrolebinding.rbac.authorization.k8s.io/kubernetes-dashboard created deployment.apps/kubernetes-dashboard created service/dashboard-metrics-scraper created deployment.apps/dashboard-metrics-scraper created
查看pod状态
1 2 3 4
kubectl get po -n kubernetes-dashboard NAME READY STATUS RESTARTS AGE dashboard-metrics-scraper-fb986f88d-n2fkv 1/1 Running 0 115s kubernetes-dashboard-6bb65fcc49-bm676 1/1 Running 0 115s
=============================================================================================================== Package 架构 版本 源 大小 =============================================================================================================== 正在安装: docker-ce x86_64 18.06.3.ce-3.el7 docker-ce-stable 41 M 为依赖而安装: audit-libs-python x86_64 2.8.5-4.el7 base 76 k checkpolicy x86_64 2.5-8.el7 base 295 k container-selinux noarch 2:2.107-3.el7 extras 39 k libcgroup x86_64 0.41-21.el7 base 66 k libseccomp x86_64 2.3.1-3.el7 base 56 k libsemanage-python x86_64 2.5-14.el7 base 113 k libtool-ltdl x86_64 2.4.2-22.el7_3 base 49 k policycoreutils-python x86_64 2.5-33.el7 base 457 k python-IPy noarch 0.75-6.el7 base 32 k setools-libs x86_64 3.3.8-4.el7 base 620 k
systemctl enable kubelet Created symlink from /etc/systemd/system/multi-user.target.wants/kubelet.service to /usr/lib/systemd/system/kubelet.service.
拉取镜像
执行kubeadm时,需要用到一些镜像,我们需要提前准备。
查看需要依赖哪些镜像
1 2 3 4 5 6 7 8 9 10
kubeadm config images list W1207 18:53:23.129020 10255 version.go:98] could not fetch a Kubernetes version from the internet: unable to get URL "https://dl.k8s.io/release/stable-1.txt": Get https://dl.k8s.io/release/stable-1.txt: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers) W1207 18:53:23.129433 10255 version.go:99] falling back to the local client version: v1.15.6 k8s.gcr.io/kube-apiserver:v1.15.6 k8s.gcr.io/kube-controller-manager:v1.15.6 k8s.gcr.io/kube-scheduler:v1.15.6 k8s.gcr.io/kube-proxy:v1.15.6 k8s.gcr.io/pause:3.1 k8s.gcr.io/etcd:3.3.10 k8s.gcr.io/coredns:1.3.1
W1207 21:18:48.257967 10859 version.go:98] could not fetch a Kubernetes version from the internet: unable to get URL "https://dl.k8s.io/release/stable-1.txt": Get https://dl.k8s.io/release/stable-1.txt: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers) W1207 21:18:48.258448 10859 version.go:99] falling back to the local client version: v1.15.6 [init] Using Kubernetes version: v1.15.6 [preflight] Running pre-flight checks [WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/ [preflight] Pulling images required for setting up a Kubernetes cluster [preflight] This might take a minute or two, depending on the speed of your internet connection [preflight] You can also perform this action in beforehand using 'kubeadm config images pull' [kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env" [kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml" [kubelet-start] Activating the kubelet service [certs] Using certificateDir folder "/etc/kubernetes/pki" [certs] Generating "ca" certificate and key [certs] Generating "apiserver" certificate and key [certs] apiserver serving cert is signed for DNS names [k8s-master kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 172.16.64.233] [certs] Generating "apiserver-kubelet-client" certificate and key [certs] Generating "etcd/ca" certificate and key [certs] Generating "etcd/peer" certificate and key [certs] etcd/peer serving cert is signed for DNS names [k8s-master localhost] and IPs [172.16.64.233 127.0.0.1 ::1] [certs] Generating "etcd/healthcheck-client" certificate and key [certs] Generating "etcd/server" certificate and key [certs] etcd/server serving cert is signed for DNS names [k8s-master localhost] and IPs [172.16.64.233 127.0.0.1 ::1] [certs] Generating "apiserver-etcd-client" certificate and key [certs] Generating "front-proxy-ca" certificate and key [certs] Generating "front-proxy-client" certificate and key [certs] Generating "sa" key and public key [kubeconfig] Using kubeconfig folder "/etc/kubernetes" [kubeconfig] Writing "admin.conf" kubeconfig file [kubeconfig] Writing "kubelet.conf" kubeconfig file [kubeconfig] Writing "controller-manager.conf" kubeconfig file [kubeconfig] Writing "scheduler.conf" kubeconfig file [control-plane] Using manifest folder "/etc/kubernetes/manifests" [control-plane] Creating static Pod manifest for "kube-apiserver" [control-plane] Creating static Pod manifest for "kube-controller-manager" [control-plane] Creating static Pod manifest for "kube-scheduler" [etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests" [wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s [apiclient] All control plane components are healthy after 36.504799 seconds [upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace [kubelet] Creating a ConfigMap "kubelet-config-1.15" in namespace kube-system with the configuration for the kubelets in the cluster [upload-certs] Skipping phase. Please see --upload-certs [mark-control-plane] Marking the node k8s-master as control-plane by adding the label "node-role.kubernetes.io/master=''" [mark-control-plane] Marking the node k8s-master as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule] [bootstrap-token] Using token: 1czxp7.4tt0x3lxdcus8wer [bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles [bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials [bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token [bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster [bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace [addons] Applied essential addon: CoreDNS [addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
[WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/
[reset] Reading configuration from the cluster... [reset] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml' W1207 22:12:18.285935 27649 reset.go:98] [reset] Unable to fetch the kubeadm-config ConfigMap from cluster: failed to get config map: Get https://172.16.64.233:6443/api/v1/namespaces/kube-system/configmaps/kubeadm-config: dial tcp 172.16.64.233:6443: connect: connection refused [reset] WARNING: Changes made to this host by 'kubeadm init' or 'kubeadm join' will be reverted. [reset] Are you sure you want to proceed? [y/N]: y [preflight] Running pre-flight checks W1207 22:12:19.569005 27649 removeetcdmember.go:79] [reset] No kubeadm config, using etcd pod spec to get data directory [reset] Stopping the kubelet service [reset] Unmounting mounted directories in "/var/lib/kubelet" [reset] Deleting contents of config directories: [/etc/kubernetes/manifests /etc/kubernetes/pki] [reset] Deleting files: [/etc/kubernetes/admin.conf /etc/kubernetes/kubelet.conf /etc/kubernetes/bootstrap-kubelet.conf /etc/kubernetes/controller-manager.conf /etc/kubernetes/scheduler.conf] [reset] Deleting contents of stateful directories: [/var/lib/etcd /var/lib/kubelet /etc/cni/net.d /var/lib/dockershim /var/run/kubernetes]
The reset process does not reset or clean up iptables rules or IPVS tables. If you wish to reset iptables, you must do so manually. For example: iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X
If your cluster was setup to utilize IPVS, run ipvsadm --clear (or similar) to reset your system's IPVS tables.
The reset process does not clean your kubeconfig files and you must remove them manually. Please, check the contents of the $HOME/.kube/config file.
You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubectl get no NAME STATUS ROLES AGE VERSION k8s-master NotReady master 2m22s v1.15.6
往集群里面加入node节点
在节点node1上,按上面的提示执行命令:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
kubeadm join 172.16.64.233:6443 --token duof19.l9q3dsh4ccen4ya0 \ --discovery-token-ca-cert-hash sha256:66fad0ed5f46f5ea9a394276a77db16d26d60465ec9930f8c21aa924a5df9bb5 [preflight] Running pre-flight checks [preflight] Reading configuration from the cluster... [preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml' [kubelet-start] Downloading configuration for the kubelet from the "kubelet-config-1.15" ConfigMap in the kube-system namespace [kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml" [kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env" [kubelet-start] Activating the kubelet service [kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
This node has joined the cluster: * Certificate signing request was sent to apiserver and a response was received. * The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
在Master节点上(control-plane)上查看节点信息
1 2 3 4
kubectl get no NAME STATUS ROLES AGE VERSION k8s-master NotReady master 7m v1.15.6 k8s-node1 NotReady <none> 65s v1.15.6
docker pull quay.azk8s.cn/coreos/flannel:v0.11.0-amd64 docker tag ff281650a721 quay.io/coreos/flannel:v0.11.0-amd64 docker rmi quay.azk8s.cn/coreos/flannel:v0.11.0-amd64
安装flannel
我们也可以选择安装Calico网络插件。
在Master节点执行:
1 2 3 4 5 6 7 8 9 10 11 12
kubectl apply -f kube-flannel.yml
podsecuritypolicy.policy/psp.flannel.unprivileged created clusterrole.rbac.authorization.k8s.io/flannel created clusterrolebinding.rbac.authorization.k8s.io/flannel created serviceaccount/flannel created configmap/kube-flannel-cfg created daemonset.apps/kube-flannel-ds-amd64 created daemonset.apps/kube-flannel-ds-arm64 created daemonset.apps/kube-flannel-ds-arm created daemonset.apps/kube-flannel-ds-ppc64le created daemonset.apps/kube-flannel-ds-s390x created
查看节点信息
1 2 3 4 5
kubectl get no NAME STATUS ROLES AGE VERSION k8s-master Ready master 33m v1.15.6 k8s-node1 Ready <none> 28m v1.15.6 k8s-node2 Ready <none> 17m v1.15.6
kubectl create deploy nginx-deployment --image=nginx deployment.apps/nginx-deployment created
查看deployment状态
1 2 3
kubectl get deploy NAME READY UP-TO-DATE AVAILABLE AGE nginx-deployment 0/1 1 0 44s
发现没有READY。
查看pod状态
1 2 3
kubectl get po NAME READY STATUS RESTARTS AGE nginx-deployment-6f77f65499-htdps 0/1 ContainerCreating 0 111s
也是没有READY。继续查看详细信息。
1 2 3 4 5 6 7 8
kubectl describe po nginx-deployment-6f77f65499-htdps
... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 2m18s default-scheduler Successfully assigned default/nginx-deployment-6f77f65499-htdps to k8s-node1 Normal Pulling 2m17s kubelet, k8s-node1 Pulling image "nginx"
kubectl get po -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-deployment-6f77f65499-htdps 1/1 Running 0 26m 10.244.1.3 k8s-node1 <none> <none>
... <body> <h1>Welcome to nginx!</h1> <p>If you see this page, the nginx web server is successfully installed and working. Further configuration is required.</p> ...
kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 71m nginx-deployment NodePort 10.109.145.67 <none> 80:32538/TCP 32s
在三个节点内访问nginx
1 2 3 4 5 6 7 8
curl 10.109.145.67
... <body> <h1>Welcome to nginx!</h1> <p>If you see this page, the nginx web server is successfully installed and working. Further configuration is required.</p> ...
... <body> <h1>Welcome to nginx!</h1> <p>If you see this page, the nginx web server is successfully installed and working. Further configuration is required.</p> ...