Linux(CentOS)根据进程查找程序位置
我们可能经常会遇到这种情况,登录到服务器上,想知道某个程序的位置在哪里,或者这个程序加载的配置文件位置在哪里。
首先,查看进程信息,比如我要查看 redis 程序运行的位置。
1 | ps -ef | grep redis |
获取到了进程号:31087
1 | ll /proc/31087 |
通过上述信息我们则知道了运行程序的位置 /redis/bin/redis-server。
我们可能经常会遇到这种情况,登录到服务器上,想知道某个程序的位置在哪里,或者这个程序加载的配置文件位置在哪里。
首先,查看进程信息,比如我要查看 redis 程序运行的位置。
1 | ps -ef | grep redis |
获取到了进程号:31087
1 | ll /proc/31087 |
通过上述信息我们则知道了运行程序的位置 /redis/bin/redis-server。
记录一下通过腾迅云云直播平台开发混流操作的环境搭建。主要是在腾迅平台做一些设置,和下载一个推流软件并做相关配置。
进入腾迅云去直播控制台。
关于推流域名:直播已提供系统推流域名,亦可添加自有已备案域名进行推流。

由于是测试使用,我们就先不绑定自有域名了。
播放域名必须要有自有域名,并且已经备案,这里假设我们的备案域名是:finolo.gy。
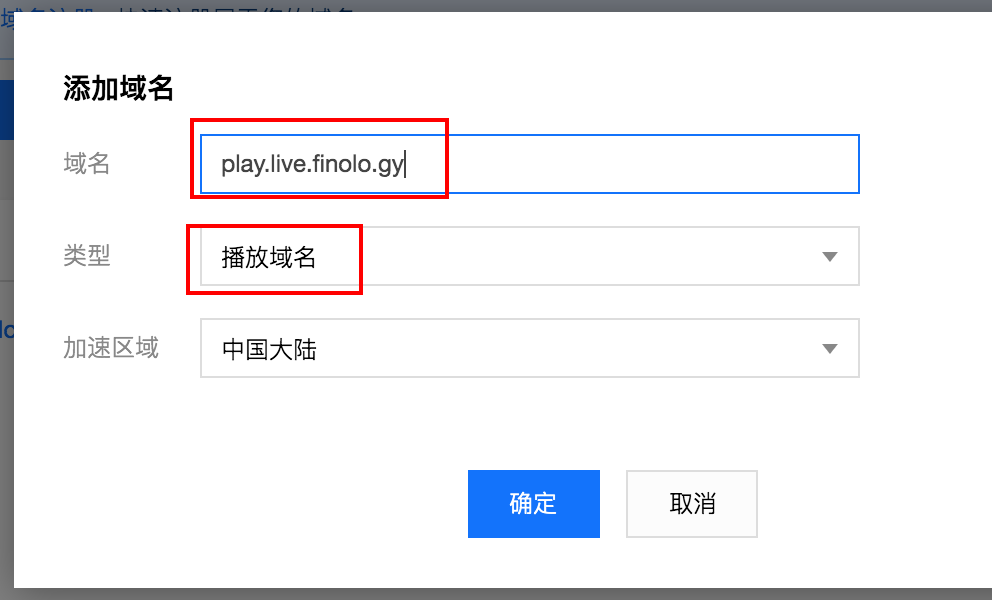
添加以后,会有红色警告提示。

去域名解析那里添加一条 CNAME 记录,主机记录为 play.live,记录值为上图的 play.live.finolo.gy.livecdn.liveplay.myqcloud.com。
绑定后很快就能生效,可以通过 nslookup 命令查看。然后刚才的红色图标报警也变成绿色了。
进入域名管理页面,点击推流域名或管理按钮,进入推流配置标签页,填写好 StreamName,就可以生成推流地址了。
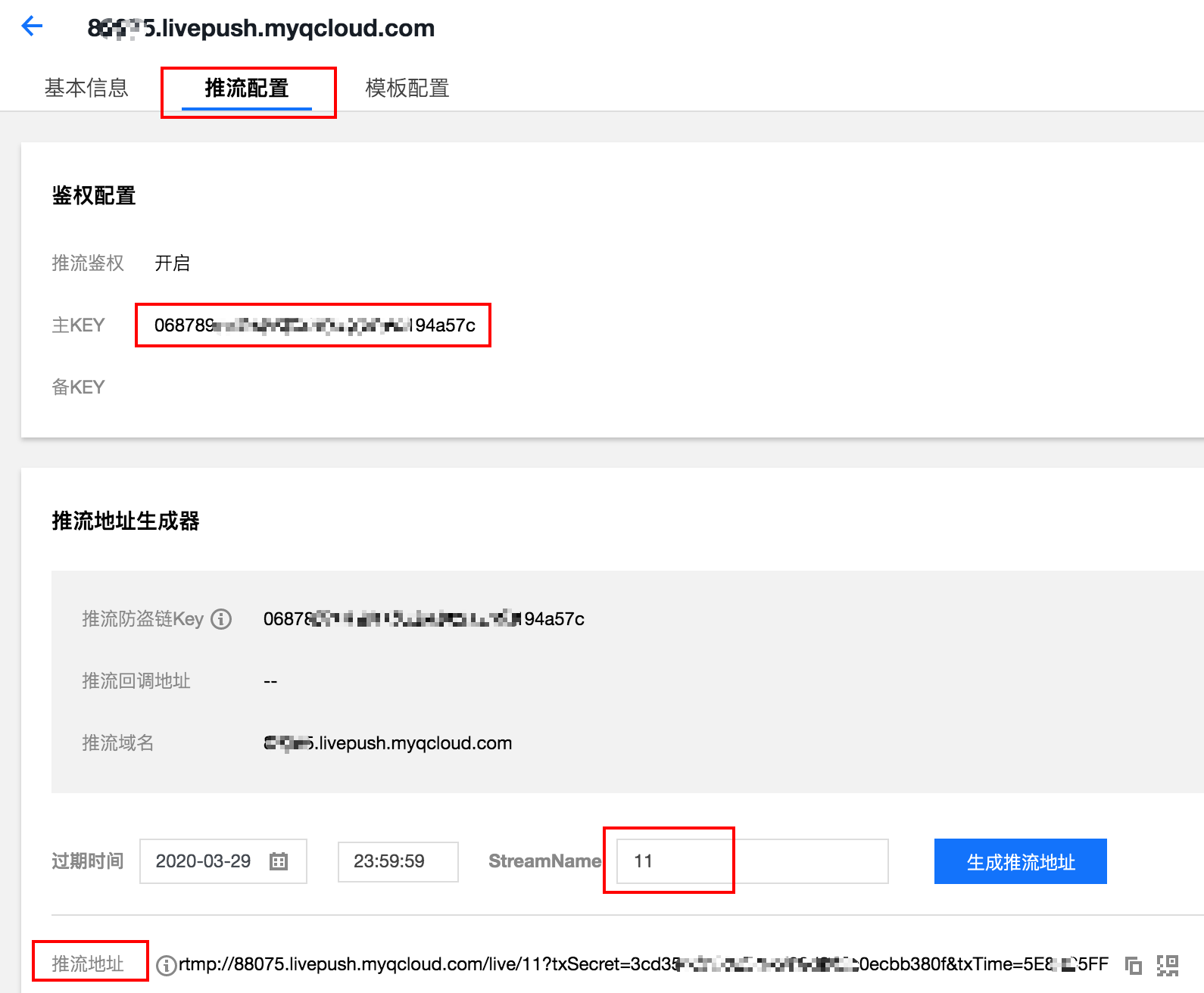
做为后端开发,一般不需要通过程序来获取推流地址,但APP端,需要推流,就需要通过程序来获取这个推流地址了。
也可以在辅助工具下面的地址生成器下面生成推流地址,这些信息也是下面我们使用 OBS 设备需要填入的。

我下载了一个 OBS 设备来推流,目前觉得还是挺好用的。
可以去 OBS 官网 https://obsproject.com/download 下载。
然后设置推流。如图:

同时需要设置一个推流的来源,我选择的是窗口捕获,这样从某个窗体捕获的视频流就采集到,并推送到前面设置的那个推流地址了。
进入 流管理 页面,我们就可以看到有一流记录在上面了。点击测试按钮,就可以看到流的内容了。非常方便后端测试了。

在 Spring Boot 项目中,我们以 json 作为返回结果时,往往不需要输出值为 null 的属性,有点多余。
有两种方法可以用。
第一种,就是在类上添加注解:@JsonInclude(JsonInclude.Include.NON_NULL)
这种方法的好处,就是可以单独处理每个类。不好的地方就是,一个输出类,其属性,以及属性的属性都是类,这样每个类都设置这个注解,有些繁琐。
第二种,在 application.yaml 里面添加如下配置:
1 | spring: |
所有的类,在序列化为 json,只要属性值为 null 的,都不会输出出来。