今天来梳理一下Grafana图表及其后面的公式。
Kubernetes / Compute Resources / Cluster
CPU Utilisation
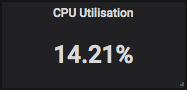
1 | 1 - avg(rate(node_cpu_seconds_total{mode="idle", cluster=""}[1m])) |
在prometheus上面查询指标
node_cpu_seconds_total{mode="idle"}
1 | node_cpu_seconds_total{cpu="0",endpoint="https",instance="k8s-master",job="node-exporter",mode="idle",namespace="monitoring",pod="node-exporter-t9ljw",service="node-exporter"} 3102.08 |
所以CPU Utilisation算的是各节点CPU利用率的平均值。
job=”node-exporter”
CPU Usage
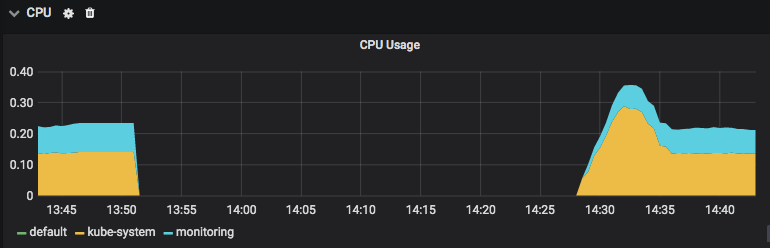
1 | sum(namespace_pod_container:container_cpu_usage_seconds_total:sum_rate{cluster=""}) by (namespace) |
在prometheus上面查询指标
namespace_pod_container:container_cpu_usage_seconds_total:sum_rate{cluster=""}
1 | namespace_pod_container:container_cpu_usage_seconds_total:sum_rate{container="addon-resizer",namespace="monitoring",pod="kube-state-metrics-65d5b4b99d-llrjd"} 0.00022111388787432652 |
Memory
1 | sum(container_memory_rss{cluster="", container!=""}) by (namespace) |
在prometheus上面查询指标
container_memory_rss
1 | container_memory_rss{container="POD",container_name="POD",endpoint="https-metrics",id="/kubepods.slice/kubepods-besteffort.slice/kubepods-besteffort-pod1a047e8b0c961b34e915140fc2a8711c.slice/docker-20e1377aeb77873fcf4ac5e4380d47f28c0f594773ba047442b00dfc6f116837.scope",image="k8s.gcr.io/pause:3.1",instance="172.16.64.233:10250",job="kubelet",name="k8s_POD_etcd-k8s-master_kube-system_1a047e8b0c961b34e915140fc2a8711c_14",namespace="kube-system",node="k8s-master",pod="etcd-k8s-master",pod_name="etcd-k8s-master",service="kubelet"} 45056 |
job=”kubelet”
Kubernetes / Compute Resources / Namespace (Pods)
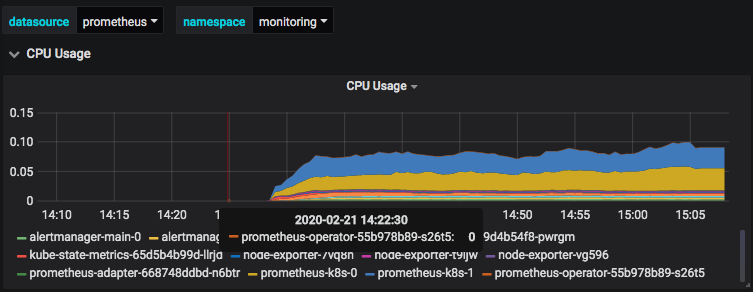
1 | sum(namespace_pod_container:container_cpu_usage_seconds_total:sum_rate{cluster="", namespace="monitoring"}) by (pod) |
Kubernetes / Compute Resources / Pod
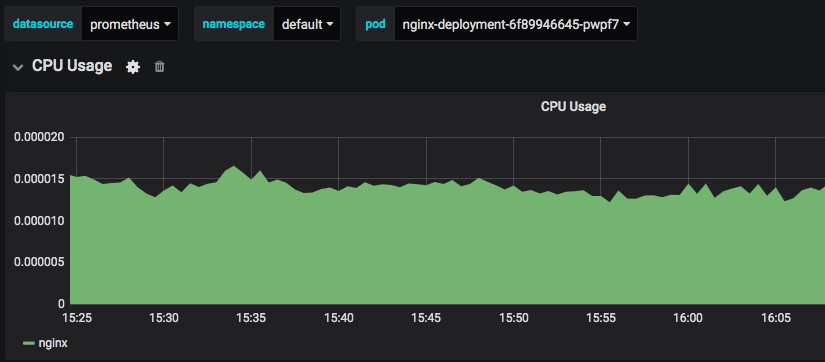
显示各个选中Pod中,各个Container的状态。
sum(namespace_pod_container:container_cpu_usage_seconds_total:sum_rate{namespace=”default”, pod=”nginx-deployment-6f89946645-pwpf7”, container!=”POD”, cluster=””}) by (container)
#
现在的逻辑就是要把container的指标打上pod的标签
1 | - job_name: 'kubernetes-cadvisor' |