kubectl apply -f operator/ customresourcedefinition.apiextensions.k8s.io/alertmanagers.monitoring.coreos.com created customresourcedefinition.apiextensions.k8s.io/podmonitors.monitoring.coreos.com created customresourcedefinition.apiextensions.k8s.io/prometheuses.monitoring.coreos.com created customresourcedefinition.apiextensions.k8s.io/prometheusrules.monitoring.coreos.com created customresourcedefinition.apiextensions.k8s.io/servicemonitors.monitoring.coreos.com created clusterrole.rbac.authorization.k8s.io/prometheus-operator created clusterrolebinding.rbac.authorization.k8s.io/prometheus-operator created deployment.apps/prometheus-operator created service/prometheus-operator created serviceaccount/prometheus-operator created
kubectl apply -f adapter/ apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created clusterrole.rbac.authorization.k8s.io/prometheus-adapter created clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created clusterrolebinding.rbac.authorization.k8s.io/prometheus-adapter created clusterrolebinding.rbac.authorization.k8s.io/resource-metrics:system:auth-delegator created clusterrole.rbac.authorization.k8s.io/resource-metrics-server-resources created configmap/adapter-config created deployment.apps/prometheus-adapter created rolebinding.rbac.authorization.k8s.io/resource-metrics-auth-reader created service/prometheus-adapter created serviceaccount/prometheus-adapter created
kubectl apply -f alertmanager/ alertmanager.monitoring.coreos.com/main created secret/alertmanager-main created service/alertmanager-main created serviceaccount/alertmanager-main created
kubectl apply -f node-exporter/ clusterrole.rbac.authorization.k8s.io/node-exporter created clusterrolebinding.rbac.authorization.k8s.io/node-exporter created daemonset.apps/node-exporter created service/node-exporter created serviceaccount/node-exporter created
kubectl apply -f kube-state-metrics/ clusterrole.rbac.authorization.k8s.io/kube-state-metrics created clusterrolebinding.rbac.authorization.k8s.io/kube-state-metrics created deployment.apps/kube-state-metrics created role.rbac.authorization.k8s.io/kube-state-metrics created rolebinding.rbac.authorization.k8s.io/kube-state-metrics created service/kube-state-metrics created serviceaccount/kube-state-metrics created
kubectl apply -f grafana/ secret/grafana-datasources created configmap/grafana-dashboard-apiserver created configmap/grafana-dashboard-controller-manager created configmap/grafana-dashboard-k8s-resources-cluster created configmap/grafana-dashboard-k8s-resources-namespace created configmap/grafana-dashboard-k8s-resources-pod created configmap/grafana-dashboard-k8s-resources-workload created configmap/grafana-dashboard-k8s-resources-workloads-namespace created configmap/grafana-dashboard-kubelet created configmap/grafana-dashboard-node-cluster-rsrc-use created configmap/grafana-dashboard-node-rsrc-use created configmap/grafana-dashboard-nodes created configmap/grafana-dashboard-persistentvolumesusage created configmap/grafana-dashboard-pods created configmap/grafana-dashboard-prometheus-remote-write created configmap/grafana-dashboard-prometheus created configmap/grafana-dashboard-proxy created configmap/grafana-dashboard-scheduler created configmap/grafana-dashboard-statefulset created configmap/grafana-dashboards created deployment.apps/grafana created service/grafana created serviceaccount/grafana created
kubectl apply -f prometheus/ clusterrole.rbac.authorization.k8s.io/prometheus-k8s created clusterrolebinding.rbac.authorization.k8s.io/prometheus-k8s created prometheus.monitoring.coreos.com/k8s created rolebinding.rbac.authorization.k8s.io/prometheus-k8s-config created rolebinding.rbac.authorization.k8s.io/prometheus-k8s created rolebinding.rbac.authorization.k8s.io/prometheus-k8s created rolebinding.rbac.authorization.k8s.io/prometheus-k8s created role.rbac.authorization.k8s.io/prometheus-k8s-config created role.rbac.authorization.k8s.io/prometheus-k8s created role.rbac.authorization.k8s.io/prometheus-k8s created role.rbac.authorization.k8s.io/prometheus-k8s created prometheusrule.monitoring.coreos.com/prometheus-k8s-rules created service/prometheus-k8s created serviceaccount/prometheus-k8s created
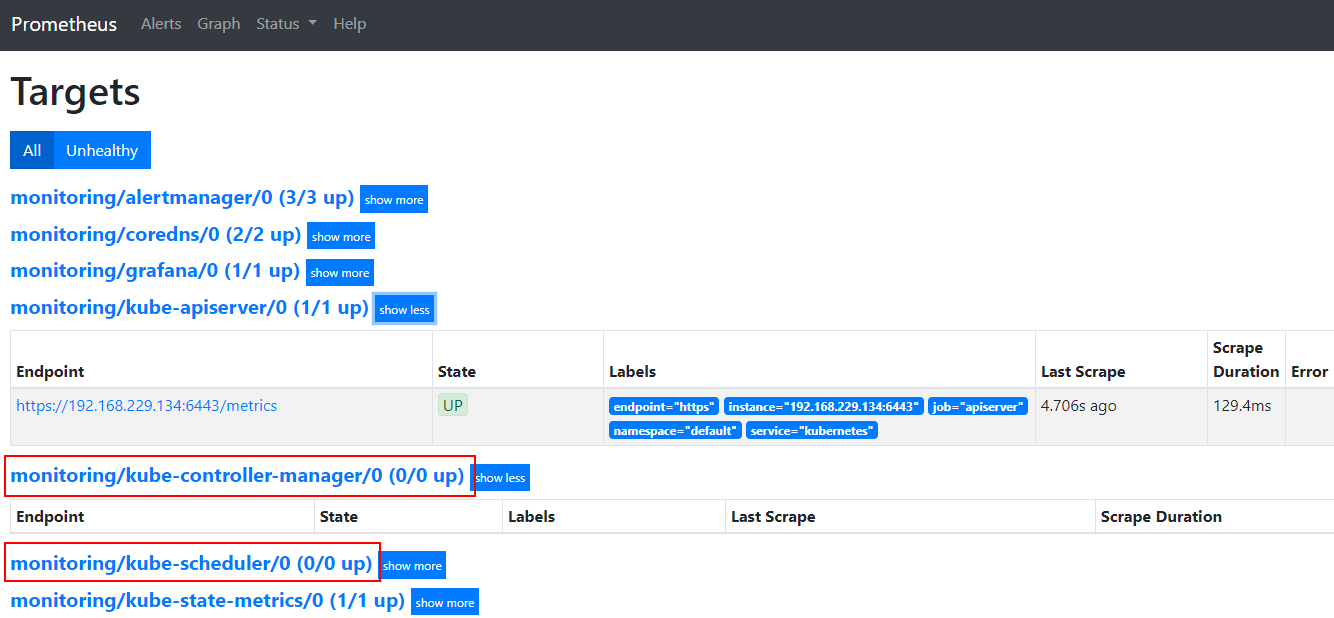
kubectl apply -f serviceMonitor/ servicemonitor.monitoring.coreos.com/prometheus-operator created servicemonitor.monitoring.coreos.com/alertmanager created servicemonitor.monitoring.coreos.com/grafana created servicemonitor.monitoring.coreos.com/kube-state-metrics created servicemonitor.monitoring.coreos.com/node-exporter created servicemonitor.monitoring.coreos.com/prometheus created servicemonitor.monitoring.coreos.com/kube-apiserver created servicemonitor.monitoring.coreos.com/coredns created servicemonitor.monitoring.coreos.com/kube-controller-manager created servicemonitor.monitoring.coreos.com/kube-scheduler created servicemonitor.monitoring.coreos.com/kubelet created